Hace unos días me he topado con Khala, un sistema open source de generación musical que me ha sorprendido por la calidad de los resultados. A diferencia de la mayoría de modelos que generan clips cortos de 10-30 segundos, Khala apunta a canciones completas con voz, instrumentación y estructura.
Las muestras del demo oficial son muy convincentes: pistas con introducción, estrofas, estribillo y final, controlables tanto con descripciones en lenguaje natural como con letras propias.
Qué hace diferente a Khala
La mayoría de generadores musicales actuales se basan en uno de dos enfoques: modelos de difusión sobre representaciones latentes (como Stable Audio o MusicGen-Melody en algunos modos) o tokens semánticos + acústicos (la línea de AudioLM o MusicGen original). Khala propone otra cosa:
- Una jerarquía de tokens acústicos RVQ de 64 capas que representa todo el audio en un espacio discreto unificado, sin separar lo semántico de lo acústico.
- Un modelo backbone que genera los tokens gruesos (las capas bajas del RVQ, las que capturan la estructura).
- Un modelo de super-resolución que completa las capas superiores, las responsables del detalle acústico y el timbre.
- Un decodificador que reconstruye la onda final.
El resultado es un pipeline más simple conceptualmente — todo vive en el mismo espacio de tokens — pero capaz de mantener coherencia musical durante minutos enteros.
El stack
El repositorio no es solo el modelo: viene con una implementación completa pensada para servirse en producción.
- Inferencia: Python con NVIDIA Megatron / Megatron-Core para la parte de modelado.
- API: FastAPI como dispatcher entre el frontend y los inference workers.
- Frontend: Vite + React, con dos modos de uso — Prompt Mode (descripción libre) y Tag Mode (etiquetas de género, instrumentos, mood, etc.).
- Despliegue: Docker con soporte CUDA.
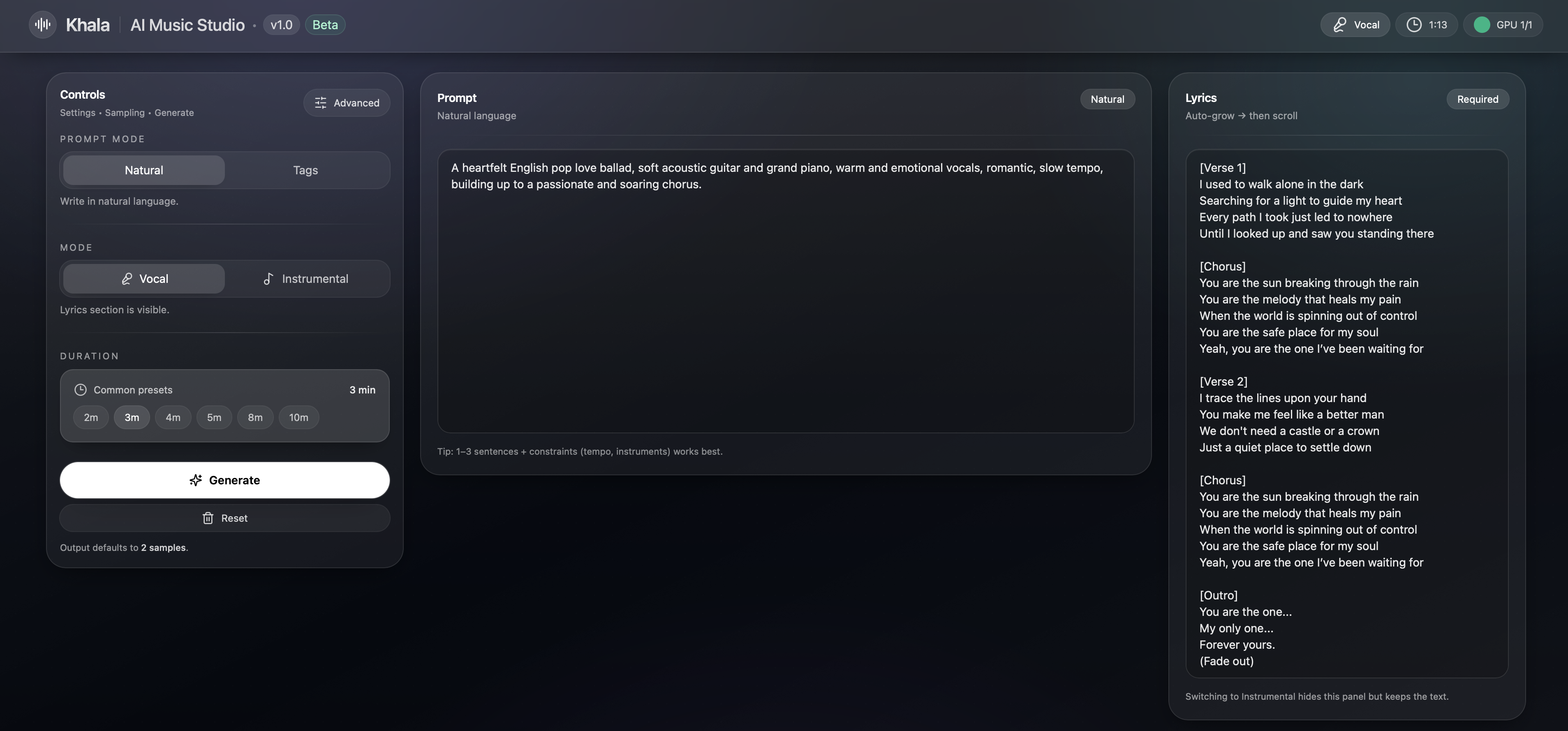 Interfaz web de Khala (modo Prompt). Fuente: repositorio oficial.
Interfaz web de Khala (modo Prompt). Fuente: repositorio oficial.
Hardware
Aquí está el peaje. Khala recomienda 24 GB o más de VRAM para la inferencia completa — una RTX 4090 o equivalente. No es algo que vayas a ejecutar en un portátil, pero está dentro del rango de una estación de trabajo personal o una instancia en la nube razonable. Los pesos están publicados en Hugging Face.
Licencia
El código del repositorio es open source, pero los pesos del modelo están bajo CC BY-NC 4.0 (Creative Commons Atribución-NoComercial). Es decir: puedes experimentar, investigar, compartir las generaciones citando la fuente, pero no usar el modelo en productos comerciales sin un acuerdo aparte. Es la misma estrategia que han adoptado muchos otros modelos generativos (Stable Diffusion en sus inicios, MusicGen, etc.): liberar el conocimiento pero proteger la vía comercial.
Por qué me interesa
Los generadores musicales propietarios como Suno o Udio producen resultados impresionantes, pero son cajas negras: no sabes qué arquitectura usan, no puedes ejecutarlos localmente, no puedes auditar qué hacen con tus prompts. Khala es de las primeras alternativas abiertas que se acerca a esa calidad y publica tanto el código como los pesos.
Que la frontera abierta esté avanzando en generación musical — un dominio dominado hasta hace poco por unas pocas empresas — es exactamente el tipo de noticia que me gusta dar.
Enlaces: